RAG 種類
Native RAG
嘗試解決內部資訊缺失的問題。
RAG 在回答前會先基於提問與資料庫中內容的語意相似度篩選出最具關連的段落 (chunk) 再將這些資訊傳給 LLM 進行回答,但受限於檢索到的 chunk 內容,因此若是詢問的問題比較全面,例如主題大綱等等,因為需要全面的資料內容,但檢索後卻使會提供給 LLM 部分內容而已,因此可預測回答準確率大概不高,但是若是法規等問題回答結果會更精確。
Graph RAG
嘗試解決 Native RAG 回答不精確、缺乏全域脈絡的問題。
GraphRAG 將非結構化文本轉為知識圖譜(entity 作為節點、relationship 作為邊),並透過社群偵測(community detection)與社群摘要,讓系統可在「主題層級」做檢索與整合,特別適合需要全域觀點的問題(如趨勢、跨領域影響、總覽型問答)。
其典型流程可概括為:
- 文件切塊(Text Chunks)
- 抽取實體與關係(Element Instances)
- 生成實體摘要(Element Summaries)
- 建立社群(Graph Communities)
- 生成社群摘要(Community Summaries)
- 對各社群回答後再彙整成全域答案(Global Answer)
Light RAG
LightRAG 同樣使用圖結構,但重點不是「以社群摘要為核心」,而是建立「實體/關係鍵值對 + 圖結構 + 向量檢索」的輕量索引。
它把檢索分成雙層:
- 低層檢索(Low-level Retrieval):聚焦具體實體、關係與細節
- 高層檢索(High-level Retrieval):聚焦抽象主題與全域語境
此設計讓 LightRAG 在維持全域理解的同時,也保留細粒度精準檢索能力,且在查詢成本與更新效率上通常更有優勢。
引言
現有 RAG 系統的局限性
依賴平面資料表示: 許多方法依賴於平面資料表示(flat data representations),限制了它們根據實體之間複雜關係來理解和檢索資訊的能力。
缺乏上下文感知: 這些系統通常缺乏維持不同實體及其相互關係之間連貫性所需的上下文感知能力,導致回應可能無法完全解決用戶查詢。
例:考慮用戶提問「電動車的興起如何影響城市空氣品質和大眾運輸基礎設施?」現有 RAG 方法可能檢索到關於電動車、空氣污染和公共交通挑戰的獨立文檔,但難以將這些信息綜合為一個連貫的回應。它們可能無法解釋電動車的普及如何改善空氣品質,進而可能影響公共交通規劃,用戶可能收到一個碎片化的答案,未能充分捕捉這些主題之間複雜的相互依賴關係。
LightRAG 模型概述
增強了系統捕捉實體之間複雜相互依賴關係的能力,從而產生更連貫和上下文更豐富的回應。
同時,LightRAG 透過「索引輕量化 + 雙層檢索」降低推理期成本:
- 索引階段:抽取實體/關係,建立可檢索鍵值與圖索引。
- 查詢階段:先拆解 query 的低階與高階關鍵詞,再分流檢索並合併上下文給 LLM 生成答案。
內文
GraphRAG 與 LightRAG 的核心差異
1. 索引結構
- GraphRAG: 以圖社群(community)為主,透過社群摘要作為主要檢索介面。
- LightRAG: 以實體/關係為鍵值索引,結合圖與向量,檢索顆粒度更細。
2. 檢索策略
- GraphRAG: 偏向社群層級檢索,擅長全域總覽,但細節補捉依賴社群摘要品質。
- LightRAG: 雙層檢索(低層細節 + 高層主題)並行,兼顧精準性與全面性。
3. 生成方式
- GraphRAG: 常見做法是「社群答案 -> 全域答案」的兩段式彙整。
- LightRAG: 將檢索到的實體/關係摘要直接組裝為上下文給 LLM 生成答案。
4. 成本與延遲
- GraphRAG: 建圖與社群摘要成本高,查詢時也可能涉及多輪 LLM 呼叫。
- LightRAG: 查詢路徑較短,通常以較少 API 呼叫與 token 完成檢索增強回答。
5. 更新能力
- GraphRAG: 新資料進來後,社群重算與摘要重建可能造成額外負擔。
- LightRAG: 支援增量更新,對新文件做局部索引後合併,較適合高頻更新知識庫。
GraphRAG 框架的整體架構
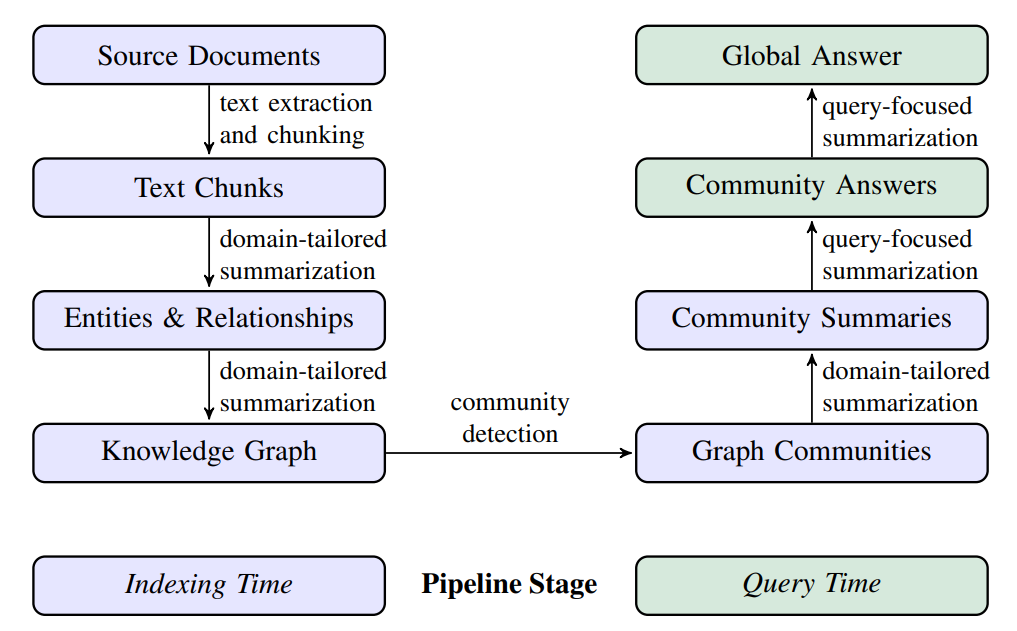 圖 1. GraphRAG pipeline(取自 GraphRAG 概論)
圖 1. GraphRAG pipeline(取自 GraphRAG 概論)
架構如圖 1 所示。GraphRAG 的核心思路是先將非結構化文本轉成知識圖譜,再透過社群偵測與社群摘要來支援全域層級的檢索與生成。
可以把流程拆成六步:
- Source Documents -> Text Chunks:將長文切成較小的 chunks,降低後續處理粒度。
- Text Chunks -> Element Instances:透過 LLM 抽取實體與關係,並反覆補全資訊。
- Element Instances -> Element Summaries:為實體與關係生成摘要,形成可供檢索的內容單位。
- Element Summaries -> Graph Communities:使用社群偵測將相關主題聚成 community。
- Graph Communities -> Community Summaries:對每個 community 生成摘要,形成主題層級知識。
- Community Summaries -> Community Answers -> Global Answer:先針對各社群回答,再整合成最終全域答案。
這種設計的優點是能處理需要「總覽 + 跨主題整合」的問題;代價則是建圖、社群摘要與多輪生成的成本較高,而且新增資料時常需要重新整理圖與社群結構。
和 LightRAG 相比,GraphRAG 更像是先把知識整理成高層次主題地圖,再沿著社群去回答問題;LightRAG 則是保留更細粒度的實體/關係索引,讓查詢時能同時兼顧細節與主題。
LightRAG 框架的整體架構
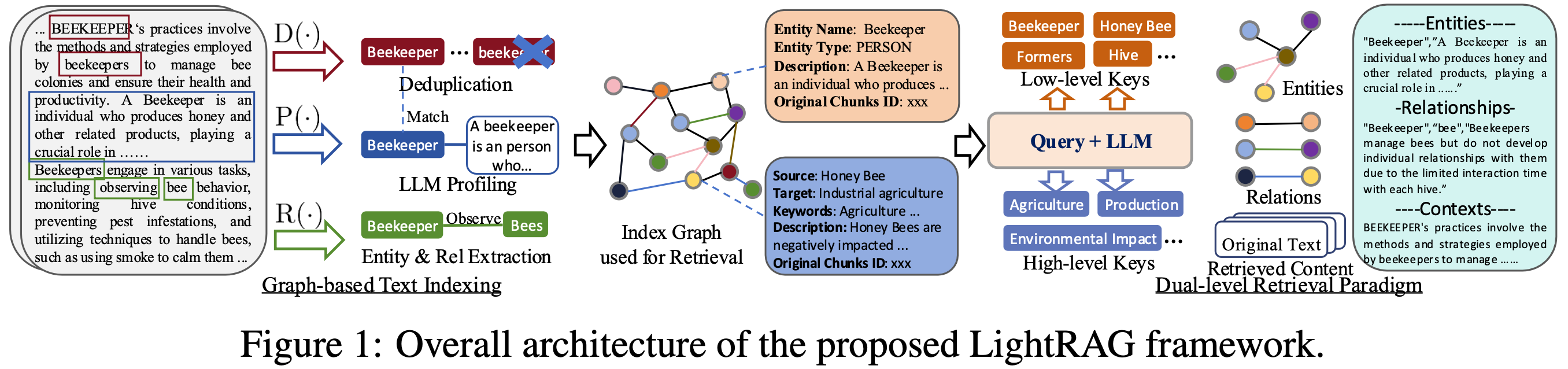
圖 2. LightRAG 框架總覽(取自原論文)
架構如圖 1 所示。
可以把它理解為三層:
- 索引層: 對文本做實體/關係抽取、剖析與去重,形成可檢索索引圖。
- 檢索層: Query LLM 抽出低層/高層關鍵詞,進入雙層檢索。
- 生成層: 將檢索回來的結構化資訊餵給 LLM,生成答案。
與 GraphRAG 的最大差別在於:LightRAG 不依賴「先社群摘要再彙總」這條主要路徑,而是用較輕量且更細顆粒的檢索單位來回應不同查詢型態。
實驗
觀察面向
若要實際比較 GraphRAG 與 LightRAG,建議至少追蹤以下指標:
- 檢索品質
- Recall@k、MRR、答案事實一致性(faithfulness)
- 生成品質
- 問答正確率、完整性、跨主題整合能力
- 系統效率
- 平均延遲(latency)、每題 token 消耗、每題 API 成本
- 更新成本
- 新資料匯入後可用時間(time-to-index)
- 增量更新是否需要大規模重建
預期結果(依文獻與社群實測)
- GraphRAG: 在全域、總覽型問題有穩定表現,但建置與維運成本偏高。
- LightRAG: 在成本、速度、更新彈性上常有優勢,且在細節與全域問題間取得較好平衡。
適用場景建議
- 選 GraphRAG: 資料更新頻率不高,且強調跨社群、全域推理與高層摘要品質。
- 選 LightRAG: 知識庫更新頻繁,且需要同時支援細節問答與主題總覽,並對成本與延遲較敏感。
結論
GraphRAG 與 LightRAG 都是為了補足 Native RAG 的限制,但設計原則不同:
- GraphRAG 側重「社群化知識組織與全域彙總」,擅長高層全貌推理。
- LightRAG 側重「輕量索引與雙層檢索」,在效率、成本、更新彈性與多粒度查詢上更均衡。
實務上可用一句話區分: GraphRAG 像是先做知識地圖總覽再回答;LightRAG 像是同時具備地圖總覽與街景導航,並以更低成本完成檢索增強生成。