RAG 種類
Native RAG
嘗試解決內部資訊缺失的問題。
RAG 在回答前會先基於提問與資料庫中內容的語意相似度篩選出最具關連的段落 (chunk) 再將這些資訊傳給 LLM 進行回答,但受限於檢索到的 chunk 內容,因此若是詢問的問題比較全面,例如主題大綱等等,因為需要全面的資料內容,但檢索後卻使會提供給 LLM 部分內容而已,因此可預測回答準確率大概不高,但是若是法規等問題回答結果會更精確。
Graph RAG
嘗試解決 Native RAG 回答不精確的問題。
Light RAG
引言
現有 RAG 系統的局限性
依賴平面資料表示: 許多方法依賴於平面資料表示(flat data representations),限制了它們根據實體之間複雜關係來理解和檢索資訊的能力。
缺乏上下文感知: 這些系統通常缺乏維持不同實體及其相互關係之間連貫性所需的上下文感知能力,導致回應可能無法完全解決用戶查詢。
例:考慮用戶提問「電動車的興起如何影響城市空氣品質和大眾運輸基礎設施?」現有 RAG 方法可能檢索到關於電動車、空氣污染和公共交通挑戰的獨立文檔,但難以將這些信息綜合為一個連貫的回應。它們可能無法解釋電動車的普及如何改善空氣品質,進而可能影響公共交通規劃,用戶可能收到一個碎片化的答案,未能充分捕捉這些主題之間複雜的相互依賴關係。
LightRAG 模型概述
增強了系統捕捉實體之間複雜相互依賴關係的能力,從而產生更連貫和上下文更豐富的回應。
內文
LightRAG 框架的整體架構
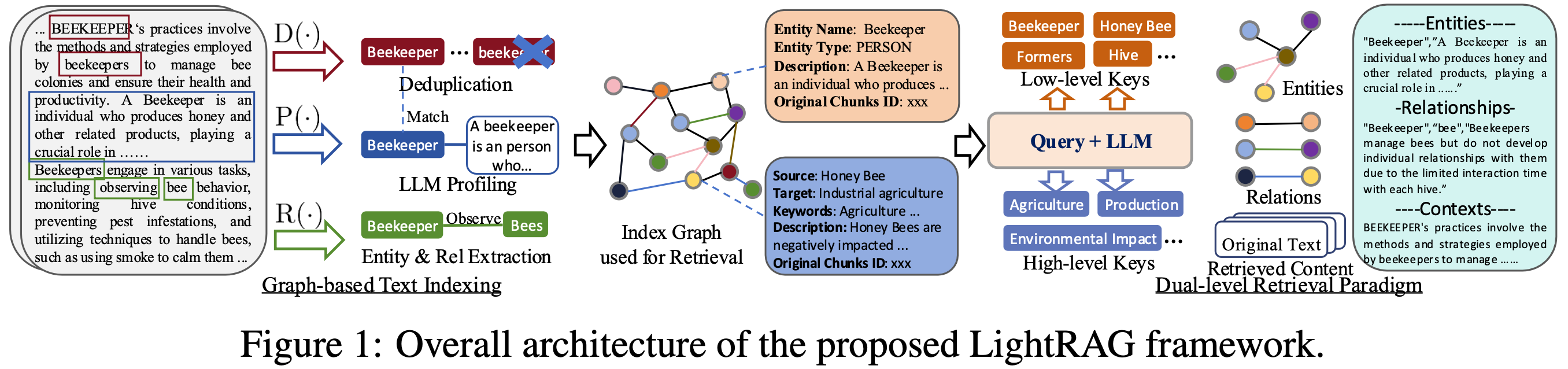
圖 1. LightRAG 框架總覽(取自原論文)
架構如圖 1 所示。