Graph RAG 基本介紹
Graph RAG
Native RAG 嘗試解決內部資訊缺失的問題,但受限於檢索到的 chunk 內容,因此若是詢問的問題比較全面,例如主題大綱等等,因為需要全面的資料內容,但檢索後卻只會提供給 LLM 部分內容而已。而為了解決全域資訊缺失的問題因而誕生了 Graph RAG。
Graph RAG 透過將非結構化文本轉換為知識圖譜來解決 Native RAG 的問題。它不僅僅是檢索文本片段,而是理解實體之間的關係,從而能夠回答更複雜、需要綜合多方面資訊的問題。
node 表示每個主體,而 edge 則是表示了每個 entity 間的關係。
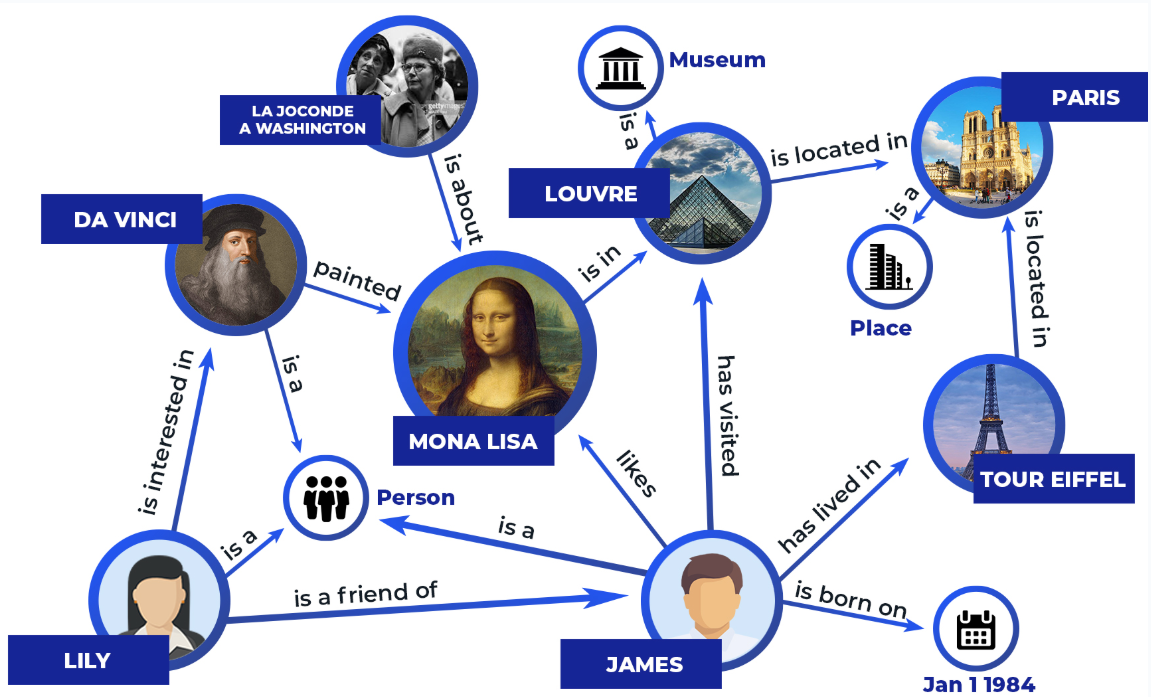 圖:Graph RAG 將文本中的實體和關係抽取出來,構建成知識圖譜。(圖片來源:Microsoft Graph RAG 介紹)
圖:Graph RAG 將文本中的實體和關係抽取出來,構建成知識圖譜。(圖片來源:Microsoft Graph RAG 介紹)
Graph RAG Pipeline
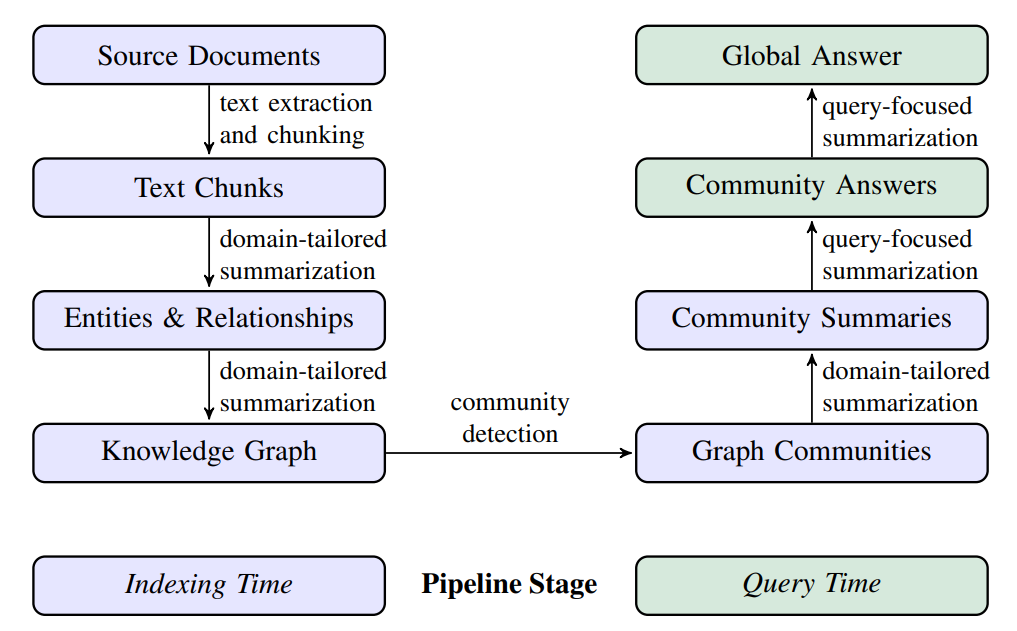 圖:Graph RAG 將文本中的實體和關係抽取出來,構建成知識圖譜。(圖片來源:Microsoft Graph RAG 介紹)
圖:Graph RAG 將文本中的實體和關係抽取出來,構建成知識圖譜。(圖片來源:Microsoft Graph RAG 介紹)
1. Source Documents → Text Chunks
將長文件轉換成小 chunks,每個 chunks size 越大則產生的 chunk 越少。
2. Text Chunks → Element Instances
使用多輪對 LLM 的問答以完善所有主體與彼此之間的關聯。
例,讓 LLM 生成資料庫中資訊的關係,接著拿生成的東西去詢問 LLM 生成的結果是否還有缺失?
若有,則再次讓 LLM 補全,一直重複到 LLM 回答可以為止。
3. Element Instances → Element Summaries
使用一個額外的 LLM 輸入 Entity 與他的 Relationship,輸出針對此 Entity Summary 的描述。
4. Element Summaries → Graph Communities
將相同主題的內容框成同樣的 Community。
使用的演算法是 Leiden community detection algorithm,原則上是相同 Community 中的 entity 間的關係越複雜越好,而不同 Community 中的 entity 間關係越簡單越好。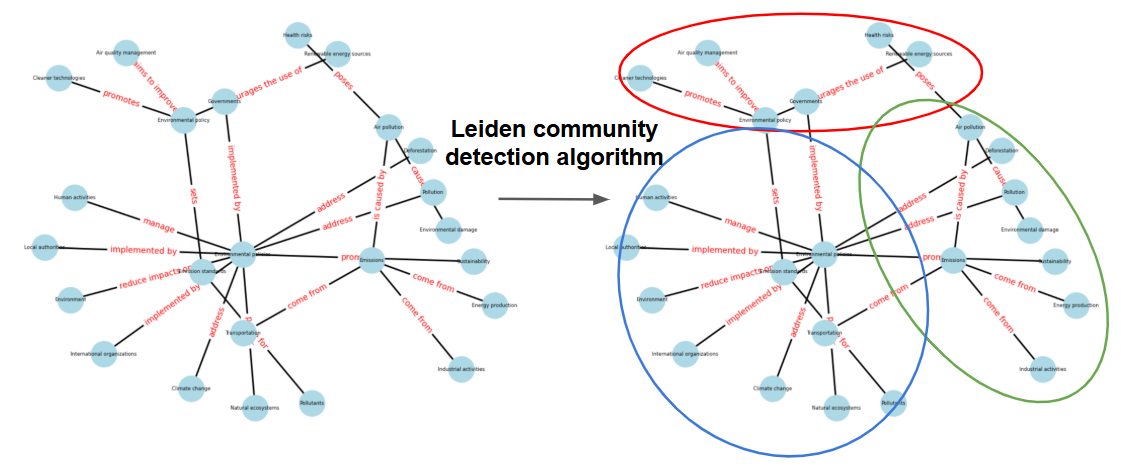 圖:Graph RAG community detection。(圖片來源:Microsoft Graph RAG 介紹)
圖:Graph RAG community detection。(圖片來源:Microsoft Graph RAG 介紹)
5. Graph Communities → Community Summaries
將同一個 community 中的 entity 都組合起來,詢問 LLM 整個此類別 community 的摘要,以第四點的圖為例,就會產生三個 Community Summaries。
若知識圖譜非常大,則可能無法將所有 entity 都傳給 LLM 則可以依照 community 中 entity 的重要性決定是否要先放入(重要性依照單一 node 的 relation 數量決定)。
6. Community Summaries → Community Answers → Global Answer
依據 Community Summaries 回答問題。
將問題拿去一一問每個 Community Summaries,得到各自的 Community 回答後,再將這些比較片面的回答整合成 global answer。
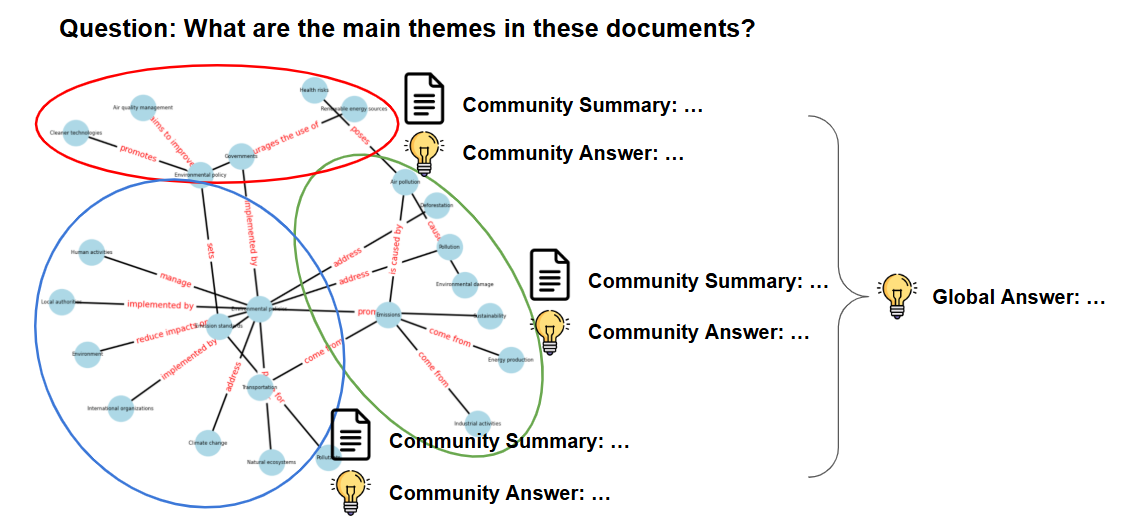 圖:Community Summaries → Community Answers → Global Answer。(圖片來源:Microsoft Graph RAG 介紹)
圖:Community Summaries → Community Answers → Global Answer。(圖片來源:Microsoft Graph RAG 介紹)
如此就可以解決 Native RAG 只看部分資訊,而使的回答缺少其餘資訊的可能。
結論
- GraphRAG 展現了更好的全域檢索能力。
- 建造知識圖譜花費的成本遠高於 Native RAG。