本文整理自:LightRAG: Simple and Fast Retrieval-Augmented Generation
作者:Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang
發佈於 arXiv,2024年10月
摘要
RAG 透過整合外部知識來源,提升 LLMs 回應的準確性與上下文相關性,但面臨過度依賴平面資料表示 (flat data representations)、上下文感知能力不足 (inadequate contextual awareness)、導致生成碎片化答案 (fragmented answers),無法捕捉複雜的相互依賴關係 (inter-dependencies)。
LightRAG,提出透過將圖結構 (graph structures) 引入文本的索引 (text indexing) 和檢索 (retrieval) 過程來解決上述問題。
引言
現有 RAG 系統的局限性
依賴平面資料表示: 許多方法依賴於平面資料表示(flat data representations),限制了它們根據實體之間複雜關係來理解和檢索資訊的能力。
缺乏上下文感知: 這些系統通常缺乏維持不同實體及其相互關係之間連貫性所需的上下文感知能力,導致回應可能無法完全解決用戶查詢。
例:考慮用戶提問「電動車的興起如何影響城市空氣品質和大眾運輸基礎設施?」現有 RAG 方法可能檢索到關於電動車、空氣污染和公共交通挑戰的獨立文檔,但難以將這些信息綜合為一個連貫的回應。它們可能無法解釋電動車的普及如何改善空氣品質,進而可能影響公共交通規劃,用戶可能收到一個碎片化的答案,未能充分捕捉這些主題之間複雜的相互依賴關係。
LightRAG 模型概述
增強了系統捕捉實體之間複雜相互依賴關係的能力,從而產生更連貫和上下文更豐富的回應。
高效雙層檢索策略:
- 低層次檢索(low-level retrieval): 側重於關於特定實體及其關係的精確資訊。
- 高層次檢索(high-level retrieval): 涵蓋更廣泛的主題和概念。
- 優勢: 透過結合詳細和概念性檢索,LightRAG 有效適應多樣化的查詢範圍,確保用戶收到符合其特定需求的相關且全面的回應。
圖結構與向量表示的整合: 透過將圖結構與向量表示整合在一起,本 LightRAG 促進了相關實體和關係的高效檢索,同時透過從所構建的知識圖中獲取相關結構信息,增強了結果的全面性。
本研究在 RAG 系統中的關注點
全面信息檢索 (Comprehensive Information Retrieval): 索引功能 ϕ(⋅) 必須善於提取全局信息,這對於增強模型有效回答查詢的能力至關重要。
高效且低成本檢索 (Efficient and Low-Cost Retrieval): 索引化的資料結構 𝒟^ 必須能夠實現快速且具成本效益的檢索,以有效處理高容量的查詢。
快速適應數據變化 (Fast Adaptation to Data Changes): 能夠迅速有效地調整數據結構以整合來自外部知識庫的新信息,這對於確保系統在不斷變化的信息環境中保持更新和相關性至關重要。
內文
LightRAG 框架的整體架構
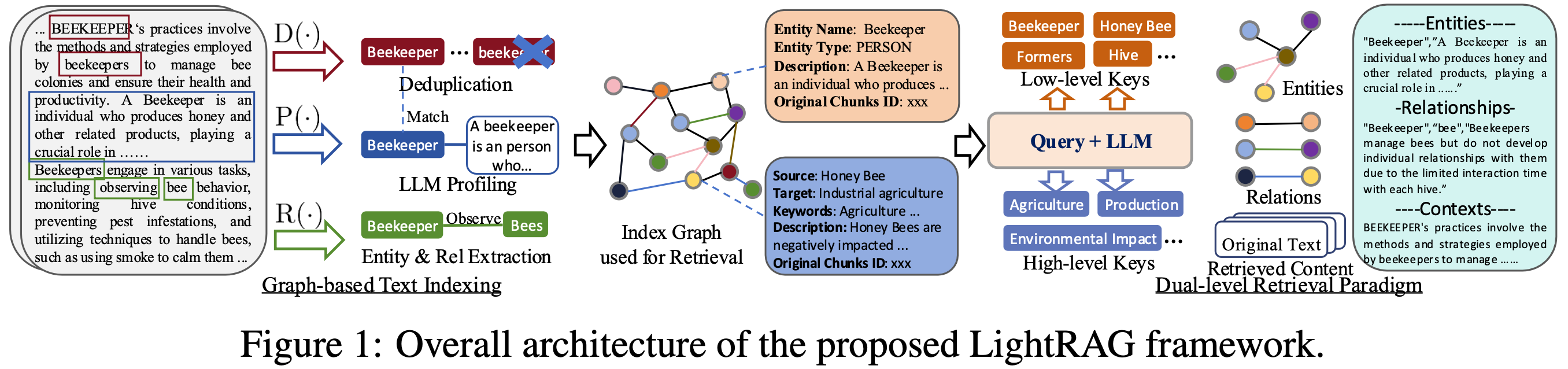
圖 1. LightRAG 框架總覽(取自原論文)
架構如圖 1 所示。
流程從原始文本塊開始,這些文本塊首先透過基於圖形的文本索引(Graph-based Text Indexing)階段進行處理,過程包含幾個關鍵子組件:實體與關係提取(Entity & Rel Extraction)、LLM 剖析(LLM Profiling)和去重(Deduplication),最後的輸出是一個用於檢索的索引圖(Index Graph)。
接著,Query LLM 接收輸入查詢,並從中生成低層級關鍵字(Low-level Keys,包括實體和關係)和高層級關鍵字(High-level Keys,包括語境和原始文本塊)。這些關鍵字隨後被送入雙層級檢索範式(Dual-level Retrieval Paradigm),此範式與「索引圖」和「原始文本塊」互動,以檢索相關資訊。最終,檢索到的資訊被傳回 Query LLM 進行檢索增強的答案生成(Retrieval-Augmented Answer Generation)。
圖中展示了以「索引圖」作為核心儲存庫,這張圖不僅用來整理新資訊(索引),也用來尋找資訊(檢索),這代表系統不再只是儲存一堆零散的文字片段,而是將知識組織成一個有結構的網路,能更智慧地找出事物之間的關聯。
此外,處理查詢的 LLM 在 LightRAG 多次出現,它不只負責生成最終答案,還會參與理解問題、引導系統去尋找相關資訊,並將找到的資料整合起來。
基於圖形的文本索引
LightRAG 透過將文件分割成更小、更易於管理的片段來增強檢索系統。這種策略允許快速識別和存取相關資訊,而無需分析整個文件 。隨後,系統利用大型語言模型(LLMs)來識別和提取各種實體(例如,名稱、日期、位置和事件)以及它們之間的關係 。透過這個過程收集到的資訊將用於創建一個全面的知識圖譜,突顯整個文件集合中的連結和見解。
圖形生成模組正式表示為:
- 實體與關係提取 (R(⋅)):
- 將文檔切分為更小的片段,方便快速檢索與處理。
- 使用大型語言模型抽取實體(如人名、地點、事件)以及它們之間的關係,構建知識圖譜。
- LLM 剖析以生成鍵值對 (P(⋅)):為每個實體與關係生成索引鍵(key)與對應摘要文本(value),形成文本鍵值對(K, V)。實體通常採用名稱作為鍵;關係也由關聯實體摘要或主題語形成鍵。
- 去重以優化圖操作 (D(⋅)):合併相同的實體與關係,以減少圖的複雜度,優化後續運算效率。
優勢:
- 全面性理解:透過多跳子圖 (multi-hop subgraphs) 強化對文本中跨關係依賴的理解。
- 檢索效率提升:採用鍵值對結構提升查詢精準度與速度,相較於傳統依賴 chunk traversal 方法更具效率。
增量更新 (Incremental Knowledge Base Update):新文檔插入時,只對該文檔進行索引解析,並與原有圖進行合併,無需重建整個索引,極大降低計算成本並提升更新速度。
雙層次檢索機制 (Dual-level Retrieval Paradigm)
- 分類查詢類型
- Specific Queries:查找特定實體的資訊。
ex. 誰寫了《Pride and Prejudice》? - Abstract Queries:探索概念性主題。
ex. 人工智慧如何影響現代教育?
- 查詢關鍵詞抽取 (Keyword Extraction)
- 將查詢分為:
- 低階關鍵詞(Low‑level)——聚焦具體實體或關係(例:人名、事件)。
- 高階關鍵詞(High‑level)——概括性主題或概念(例:制度變革趨勢)。
- 低階檢索 (Low‑Level Retrieval):透過低階鍵精確定位實體與其屬性或鄰近關係。
- 高階檢索 (High‑Level Retrieval):透過高階鍵尋找涵蓋廣泛主題或總覽資訊。
- 圖結構與向量結合檢索
- 結合知識圖結構與向量表示(vector embeddings),在進行查詢時同時考量局部(local)與全局(global)語義。
- 並引入高階相關結構資訊(如一跳鄰居)加強檢索結果的完整性與關聯度。
檢索增強答案生成
使用檢索回來的資料,將所有相關的實體與關係摘要(由 profiling function 生成;P(⋅))作為 LLM 的上下文輸入。
結合查詢與上下文生成回答,將查詢緊接相關資料餵給 LLM,生成上下文合宜、符合需求的回答。
複雜度分析
索引階段:對文本進行實體與關係抽取時,需對每個文本片段呼叫一次 LLM,不增加額外系統負擔。
檢索階段:相較於傳統高成本的 GraphRAG 社群遍歷,LightRAG 採用向量搜索與圖結構結合方式──只需一次 API 呼叫與少量 token,即完成檢索。
結論重點整理
- 圖結構索引(Graph-based Indexing)
- 以實體與關係為核心建構知識圖,支援去重與增量更新,不必重建全索引。
- 雙層檢索(Dual-level Retrieval)
- 低階檢索:精確定位實體與細節資訊。
- 高階檢索:捕捉抽象主題與全局脈絡。
- 兩者結合確保 全面性 + 精準性。
- 向量與圖結合(Hybrid Retrieval)
- 結合向量相似度與多跳圖結構檢索,兼顧語義相關與結構關聯。
- 低成本高效率
- 檢索階段僅需一次 API 呼叫、百級 token,較 GraphRAG 大幅節省計算與金錢成本。
- 動態適應性
- 能即時合併新知識圖節點,適合動態更新的大型知識庫(如法律、醫療、科研)。
LightRAG vs GraphRAG
| 面向 | LightRAG | GraphRAG |
|---|---|---|
| 索引結構 | 基於 圖結構(Knowledge Graph)+ 向量索引,以實體與關係為鍵值對(Key-Value)存儲,支援去重與增量更新 | 基於 圖結構社群(Graph Community),以社群摘要為檢索單位 |
| 檢索策略 | 雙層檢索:低階(細節)+ 高階(主題)並結合多跳圖檢索與向量相似度 | 單層檢索:依社群摘要進行檢索,缺乏細粒度與多層結合 |
| 生成過程 | 檢索到的實體與關係摘要直接送入 LLM,結構化輸入更精準 | 將社群摘要送入 LLM,依社群內容生成答案 |
| 檢索成本 | 一次 API 呼叫 | 多次 API 呼叫 |
| 增量更新 | 支援 快速合併更新,僅更新新文檔的圖索引 | 需重建整個社群報告,成本高 |
| 資訊完整性 | 低階檢索補足細節,高階檢索抓全局,全面性佳 | 依賴社群摘要,可能遺漏細節 |
| 適用場景 | 資料頻繁更新、大型知識庫、多層次查詢需求 | 資料相對靜態、偏向高層總覽查詢 |