本文整理自:A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models
作者:Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
發佈於 arXiv,2024年5月
摘要
大型語言模型(LLMs)雖展現強大生成能力,但受限於內部知識與幻覺問題。檢索增強生成(Retrieval-Augmented Generation;RAG)透過即時檢索外部資訊,提升回應的可靠性與時效性。本文整理 RA-LLMs 的架構、訓練策略與應用,並探討其面臨的挑戰與未來發展,展現檢索對提升 LLM 實用性的關鍵價值。
前言
檢索增強生成(RAG)技術透過結合資訊檢索與大型語言模型(LLMs),補足模型知識不足與幻覺問題,近年受到廣泛關注。LLMs 雖具強大生成能力,卻常受限於知識時效與專領域應用,而 RA-LLMs 則透過檢索外部資料提升生成品質。
背景
大型語言模型
應用
- 在特定資料集上進行微調,LLM 可以適應各種下游任務,使其能夠專注於特定領域或應用。
架構:
- Encoder-only 模型,雙向編碼,可同時考慮單詞左右語境。
ex. BERT - Decoder-only 模型,單向生成(左至右),根據前文預測下個字元。
ex. GPT - Encoder-Decoder 模型,將輸入編碼後,再由解碼器生成對應輸出。
ex. T5
- Encoder-only 模型,雙向編碼,可同時考慮單詞左右語境。
提示學習
提示工程(Prompt Engineering)
因為 LLM 的參數量通常非常龐大,因此提示學習的發展可使 LLM 不需為了特定任務進行大量微調,就可以實現各項任務。
缺點:當缺乏專業領域知識時,生成結果可能不夠精確。
上下文學習(In-Context Learning, ICL)
為提示學習的一種形式,透過在提示中提供範例示範,讓 LLM 觀察並學習任務模式。
缺點:成效高度依賴範例品質、當缺乏必要知識或資訊時,可能導致生成結果不理想。
為克服這些問題,發展出 RAG(檢索增強生成)技術,RAG 結合檢索與生成,提升 LLM 在多任務中的表現與適應性。
內文
LLMs 時代的 RAG 架構大致包含檢索、產生和增強三個主要流程。
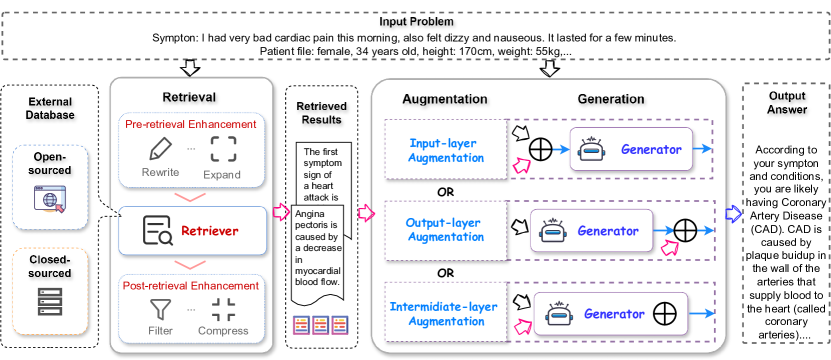
圖 1:RAG 系統總覽,涵蓋檢索、生成與增強三大流程。來源:原論文
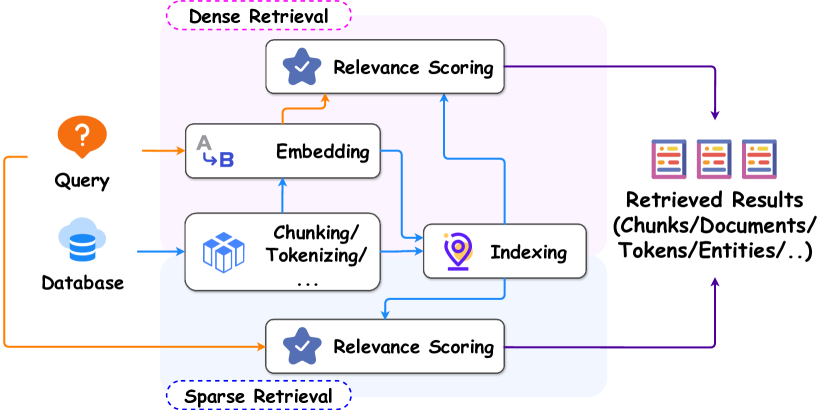
圖 2:RAG 在 RA-LLM 中的流程圖,展示各模組間的互動。來源:原論文
Retrieval
RAG 旨在從外部知識源提供關鍵訊息給 LLM。
Retriever Type
依照資訊編碼區分。
- 稀疏檢索(Sparse Retrieval):直接匹配詞彙並依頻率排名。
- 稠密檢索(Dense Retrieval):將查詢與文檔嵌入為向量,透過語意相似度檢索。
Retrieval Granularity
檢索單位的選擇對效能與計算成本有重大影響。
- Chunk(passages): 包含緊湊且完整的資訊,冗餘和不相關性較少,是 RAG 中主流的檢索文本粒度。
- Token: 實現更快的搜尋,但會給資料庫儲存帶來更多負擔。適用於需要稀有模式或領域外資料的情況。
- Entity: 實體檢索是從知識而非語言的角度檢索,對於以實體為中心的任務更有效,並且與詞元檢索相比,在空間上更高效。
Retrieval Enhancement strategies
檢索前優化(Pre-retrieval)
Query Expansion (查詢擴展):透過加入相關詞彙或概念來擴大原始查詢的範圍。例如,利用大型語言模型 (LLM) 生成偽文件,並從中提取相關資訊來擴展查詢,有助於消除歧義並引導檢索器。
Query Rewrite (查詢重寫):旨在重新彌合原始查詢,使其更適合檢索。這可能涉及澄清查詢意圖、使其更精確,或是將其轉換為檢索功能更容易理解的形式。例如,利用 LLM 將原始問題重寫為更利於檢索的版本。
舉例,多次詢問模型他的檢索資料是否正確。Query Augmentation (查詢增強):將原始查詢與初步生成的內容結合,形成一個新的查詢。這種策略可以增加查詢與潛在相關文件之間的詞彙和語義重疊,有助於檢索出更多有助於答案生成的資訊。
檢索後優化(Post-retrieval)
重排序與過濾
對檢索到的文件進行重新排序,將最相關的資訊排在前面,並過濾掉不相關或低品質的文件。例如,透過不同的檢索方法組裝文件並進行重排序,以提升檢索結果的穩健性。雜訊過濾與整合
處理檢索到的資訊中可能存在的雜訊或不相關內容,以避免其對生成過程產生負面影響。同時,將清洗過的資訊有效地整合進生成模型。壓縮與摘要
針對檢索到的長篇文件,進行壓縮或生成摘要,以解決大型語言模型輸入長度限制的問題。例如,將檢索到的文件處理成文本摘要,再用於模型生成。
Database
RA-LLM 的檢索資料庫可為封閉式或開放式來源。
- 封閉式資料庫: 通常以鍵值對 (key-value pairs) 的形式儲存知識。
- 開放式資料庫: 利用搜尋引擎(如 Bing、Google)獲取即時資訊。
生成(Generation)
生成模組的設計高度依賴於下游任務需求,因而得以適應不同的任務需求。
可調參數生成器(白箱,Parameter-Accessible Generators)
Encoder-Decoder
- 擁有獨立的編碼器(Encoder)與解碼器(Decoder),分別處理輸入與生成的目標。
- Encoder 先將輸入編碼為上下文表示,Decoder 以 Cross-Attention 讀取 Encoder 輸出,逐步生成結果。
- 模型的目標是「根據編碼後的輸入與先前生成的結果,預測下一個 token」。
輸入:請介紹 Transformer。 Encoder 編碼後 → [內部上下文表示] Decoder 讀取表示 → 生成:Transformer 是一種...Decoder-only
- 沒有獨立的編碼器。
- 輸入(如問題、提示) 和 目標(要生成的內容) 會被串接成同一序列,並從左到右進行處理。
- 模型的目標是學會「根據前面內容,預測下一個 token」。
輸入:請介紹 Transformer。 模型看到的內容:請介紹 Transformer。<接著是生成的回答...>
不可調參數生成器(黑箱,Parameter-Inaccessible Generators)
無法直接修改模型本身,且難以進行微調,因此更側重於優化檢索和增強的過程。它們的目標是透過為輸入 (prompts) 提供更優質的知識、指導或範例來增強 Generator 的性能。
增強(Augmentation)
Input-Layer Integration:
串聯整合:如 In-Context RALM (Ram et al., 2023),將原始輸入與所有檢索文件串聯為單一序列輸入生成模型。
- 問題:輸入長度易超過模型處理上限,需移除部分詞元,可能導致資訊遺失。
平行整合:如 FID (Izacard and Grave, 2021b)、Atlas、REPLUG,將每個檢索文件獨立編碼,僅在後續步驟聚合結果。
- 優點:更能擴展至大量上下文,減少資訊丟失風險。
通常,大多數基於黑盒生成的 RAG 方法都採用此法,因為生成模型的中間層和輸出分佈都無法存取。
Output-Layer Integration:
一種後處理 (post-hoc) 的檢索增強方式,它不直接干預生成模型的內部運作或其生成過程,而是在模型產生初步結果之後,才將檢索到的資訊與這些結果進行結合。
Intermediate-Layer Integration:
在生成模型內部的中間層注入檢索資訊,相較於輸入層與輸出層整合,屬於 半參數式(Semi-parametric) 的強化方式,具有更高的資訊融合深度與潛力。
3.4.Retrieval Augmentation Necessity and Frequency
基於 LLM 的生成中,檢索操作旨在補充知識以增強生成。儘管檢索增強模型前景光明,但若不加區分地使用不相關的段落進行增強,可能會覆蓋 LLM 已有的正確知識,導致錯誤回應,甚至使幻覺率翻倍。因此,對於檢索增強型 LLM (RA-LLMs) 來說,準確回憶先驗知識並僅在必要時選擇性地整合檢索資訊至關重要,這是實現穩健 RA-LLMs 的關鍵。
檢索必要性判斷
大多數方法基於 LLM 的初步答案或內部推理結果來判斷是否需要檢索:
- 特殊標記控制:如 Self-RAG,引入特殊標記評估檢索必要性並控制行為。
- 迭代提示決策:設計迭代提示決定生成中是否需要額外資訊。
- 基於信賴度 (Logits Confidence):傳統 RAG 中透過評估生成模型輸出的 logits 信賴度來判斷。如 FLARE,當 logits 低於閾值時動態觸發 RAG。
- 協同檢測:如 SlimPLM,利用輕量級代理模型生成「啟發式答案」檢測 LLM 缺失知識,並用於查詢重寫以促進檢索。
檢索頻率 (Retrieval Frequency)
檢索頻率(或稱檢索步長)是決定生成過程中檢索使用程度的重要設計考量,影響模型的效率和有效性。當不考慮檢索必要性時,檢索頻率通常是預定義和固定的,主要有三種設定:
一次性檢索 (One-time retrieval):
- 方式:在生成過程開始時只調用一次檢索功能,檢索所有所需資訊,然後提供給生成模型。
- 適用場景:外部資料庫資訊需求對 LLM 來說很明確的情況。
- 限制:對於需要長篇輸出的任務(如開放域摘要),預先檢索的文件可能不足以支持整個生成序列,需要生成中進行檢索操作。
- 範例:REALM。
每 N 個詞元檢索 (Every-n-token retrieval):
- 方式:在生成過程中每隔 N 個詞元觸發一次檢索。
- 適用場景:需要持續資訊補充的長篇生成任務。
- 範例:In-Context RALM、RETRO。
每個詞元檢索 (Every-token retrieval):
- 方式:在生成過程中,為每個詞元的預測都檢索資訊。
- 頻率:最頻繁的檢索策略。
- 範例:kNN-LM。
權衡: 總體而言,檢索頻率影響 RAG 方法的有效性和效率。更頻繁的檢索通常帶來更好的性能,但也顯著增加計算成本。
RA-LLMs 訓練策略概述
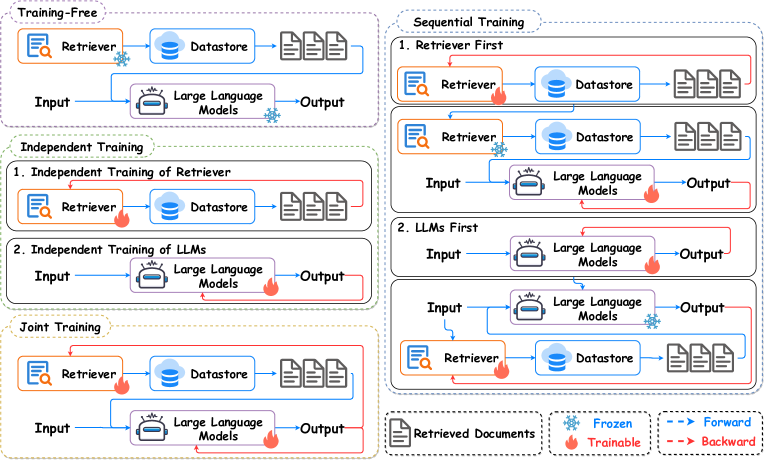
圖 3:RA-LLMs 訓練策略總覽,涵蓋免訓練與需訓練方法。來源:原論文
免訓練方法(Training-Free)
Prompt Engineering-based Methods
將檢索到的外部知識,直接整合進 LLM 的提示(Prompt),作為上下文輔助模型生成。
舉例,In-Context RALM 在不改動 LLM 參數的情況下,直接將檢索到的文件插入於原始提示之前,增強生成過程。IRCoT 則交錯進行 chain-of-thought(CoT)生成與知識檢索步驟,使每一步推理都能檢索到更相關的資訊。GENREAD 不是從大型語料庫檢索知識,而是先讓 LLM 根據查詢生成上下文文件,再根據這些上下文與問題產生答案。SKR 則引導 LLM 判斷是否能僅依靠內部知識回答問題,若不足再選擇性調用檢索器,靈活結合內外部知識。TOC 針對模糊問題,先檢索相關知識,並遞迴將問題拆解為多個明確子問題,最終聚合生成長篇答案。
- 特點:
- 無需模型訓練
- 靠設計合理的提示與檢索流程提升效果
Retrieval-Guided Token Generation Methods
透過檢索結果來調整 LLM 的 Token 預測分布,影響每一步的生成。
舉例,例如 KNN-LMs 會根據當前查詢從資料庫檢索出 k 個最相關的上下文,計算鄰近分布,並將其與原模型的輸出分布進行插值校正,以提升生成結果的準確性。Rest 則以非參數檢索資料庫取代傳統的參數式草稿模型,根據當前上下文檢索相關 token,輔助推測式生成(speculative decoding)。
- 特點:
- 不更改模型權重
- 通常作為後處理或推測性生成的輔助
※ 這兩類免訓練方法,分別著重於:
- 提示工程 — 調整輸入
- 生成控制 — 調整輸出過程
需訓練方法(Training-Based)
- Independent Training
獨立訓練方法會將 RAG 流程中的每個組件分開、獨立地進行訓練,這意味著在訓練過程中,這兩個組件之間沒有任何交互作用。
目的與優勢:
相較於無需訓練的方法,獨立訓練能有效提升 RAG 模型的性能。
1. 訓練 LLMs 以更好地利用檢索到的知識。
2. 訓練檢索器以彌合資訊檢索與語言生成之間的差距。
檢索器類型: * 稀疏檢索器 (Sparse Retriever) : 這類檢索器通常利用稀疏特徵,例如詞頻,來表示文件,並根據任務特定的指標(如 TF-IDF 和 BM25)計算相關性分數 。
* 密集檢索器 (Dense Retriever) :
密集檢索器則採用深度神經網絡將查詢和文件編碼成密集表示 (dense representations)。然後,通常使用內積計算相關性分數並檢索相關的外部知識。序列訓練透過協調訓練的方式,尋求更深層次的整合效果。
Sequential Training
序列訓練方法則採取分階段的訓練方式。首先訓練一個模組(例如檢索器),然後再利用這個訓練好的模組去指導另一個模組(例如生成器)的調整過程,目的在改善模組間的協同作用。訓練流程: 序列訓練通常分為兩個階段
- **初始預訓練:**首先對檢索器或生成器中的一個模組進行獨立的預訓練。
- **固定與訓練:**一旦其中一個模組完成預訓練,它就會被固定(freeze)下來,而另一個模組則在其輔助下進行訓練。
優勢與靈活性:
- 協同增益:與獨立訓練相比,序列訓練的優勢在於可訓練的模組能夠受益於固定模組的引導和協助,從而更好地適應彼此。
- 利用現有模型:值得注意的是,許多已經預訓練好的強大模型(例如 BERT、CLIP、T5)可以直接作為固定模組使用,從而省略了初始的預訓練步驟,進一步提高了效率。
根據檢索器和生成器之間的訓練順序,序列訓練可分為兩大類:
- 檢索器優先 (Retriever First):
此類方法首先訓練檢索器,然後將其固定,再訓練生成器。 - LLMs 優先 (LLMs First):
此類方法則相反,先訓練 LLM,再將其固定,然後訓練檢索器。
Joint Training
聯合訓練方法則是同時訓練檢索器和生成器,這種方式是為了讓兩個模組在訓練過程中相互協調、共同進步。