本文整理自:Re2G: Retrieve, Rerank, Generate
作者:Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Rajaram Naik, Pengshan Cai, Alfio Gliozzo
發佈於 arXiv,2022年7月
摘要
大型 Transformer 模型在處理複雜任務時雖然表現強大,但在應對知識密集型任務時,仍會面臨顯著的計算成本與記憶體限制。此研究指出,非參數記憶和檢索技術能有效解決這些挑戰。
基於此,Re2G 模型應運而生,它創新地整合了神經初始檢索與重新排序機制,並以 BART 框架為基礎進行序列到序列的生成。Re2G 的核心創新之處在於其獨特的重新排序功能。這使得模型能夠智慧地整合來自不同檢索源的結果,即使這些源的分數不可比較,例如同時融合傳統的 BM25 算法與神經檢索(如密集段落檢索,DPR)。透過引入重排序 (Reranker) 組件,模型得以統一處理並最大化初始候選池的質量。此外,Re2G 還引入了線上知識蒸餾方法,實現了整個檢索與生成管道的端到端訓練。這種訓練方式將系統的所有組件串接成一個整體模型,直接以最終目標作為損失函數進行優化,從而無需分階段訓練,有效提升了系統的整體性能。
※ 在機器學習領域,「端到端訓練」(End-to-End Training)指的是將整個系統的所有組件(如檢索、重排序、生成)串接為一個整體模型,直接以最終目標(如生成正確答案)作為損失函數,反向傳播優化所有參數。這種方式不需分階段分別訓練各模組,而是讓模型自動協調各部分,最大化整體性能。
基本架構介紹
RAG(Retrieval-Augmented Generation)與 Re2G(Retrieve, Rerank, Generate)架構模組如下圖所示:
圖 1. RAG 基本架構圖:RAG 基礎流程包含檢索器與生成器,將查詢與檢索到的外部知識片段一同輸入生成模型,產生最終回答。

圖 2. Re2G (Retrieve, Rerank, Generate) 架構圖:進階版本在檢索後加入重排序(Rerank)模組,對候選片段進行排序優化,提升檢索結果品質與生成相關性。
RAG 架構
- 檢索器(Retriever):從語料庫中檢索相關段落
- 生成器(Generator):基於檢索結果生成回答
Re2G 架構
- 初始檢索層(Initial Retrieval Layer):神經檢索 + 關鍵字檢索
- 重排序層(Reranker Layer):融合多種檢索結果並重排序
- 生成層(Generation Layer):基於重排序結果生成最終輸出
這種分層設計使 Re2G 能靈活結合多種檢索技術,並透過重排序提升候選質量,最終增強生成效果。
Re2G 核心概念與創新突破
Re2G 的兩大創新突破,分別體現在多源檢索結果的融合能力與創新的端到端訓練策略。 首先,Re2G 的重排序方法打破了傳統檢索分數不可比的限制,能夠有效融合來自不同檢索機制的候選結果。其次,作者提出一種改良的知識蒸餾策略,使得整個系統能僅依賴目標序列輸出進行訓練,實現從初始檢索、重排序到序列生成端到端改善。這項設計解決了當重排序器主導運算後,查詢編碼器將無法從生成損失中獲得有效梯度的問題。透過在線知識蒸餾,Re2G 讓重排序器成為查詢編碼器的指導,重新建立了梯度流通路,深化多模組系統間的互動訓練。
主要流程是從大型語料庫中檢索相關段落,隨後對這些初步檢索到的段落進行精確的重排序,最後基於重排序後的結果生成最終的輸出序列。
檢索相關段落
從大型語料庫中,透過高效的初始檢索模型(如 DPR 或 BM25)篩選出與查詢相關的候選段落。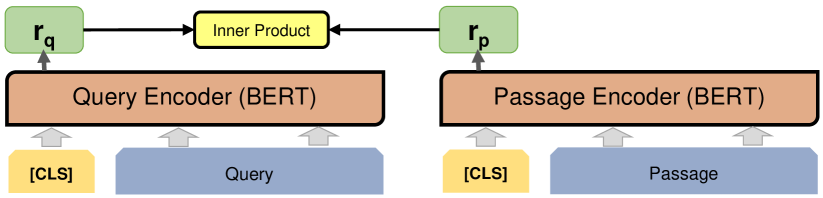
圖 3:表示模型(Bi-Encoder)運作方式:查詢(Query)與段落(Passage)分別透過獨立的 BERT 編碼器轉換為向量表示(rq 與 rp),之後透過 向量內積(Inner Product) 計算相似度,作為檢索排序的依據。精確的重排序
對初步檢索到的候選段落,使用互動模型(Reranker)進行相關性重排序。
此階段的關鍵創新在於能夠整合多種來源的檢索結果,例如:- BM25:基於關鍵字的傳統檢索,分數反映字詞匹配頻率
- DPR:基於語意向量的神經檢索,分數來自內積相似度
然而,這些檢索分數性質不同,直接比對會產生偏誤。
為此,Re2G 引入 獨立的 Reranker 模組,將不同檢索來源的候選進行統一評分,重排序後產出可比較的結果。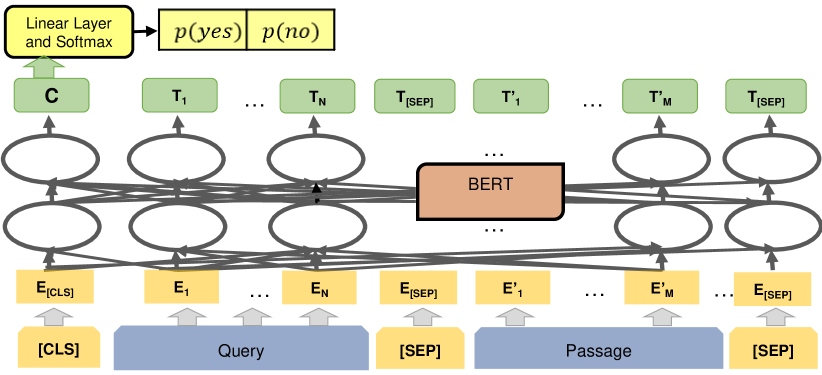
圖 4:互動模型(Interaction Model)運作方式 — 查詢與段落聯合輸入 BERT,透過交叉注意力捕捉語義關聯,最終由 [CLS] 預測相關性分數。基於重排序結果的生成
最終,將排序靠前的 Top-K 段落,與查詢共同輸入到序列生成模型(如 BART)中,生成目標回答或回應。
Re2G 模型架構詳解
初始檢索層:DPR與BM25的協同作用
目的是建立一個包含潛在相關段落的候選池,在此階段結合了兩種互補的檢索方法:
DPR (Dense Passage Retrieval) 密集段落檢索:DPR 採用雙編碼器表示模型,其中查詢編碼器和段落編碼器(兩者均基於 BERT)獨立生成查詢和段落的表示向量。這種獨立編碼的設計允許在檢索前預先計算語料庫中所有段落的向量,並使用近似最近鄰 (ANN) 索引。在推斷時,輸入查詢會使用 DPR 查詢編碼器進行編碼,並從 HNSW 索引中快速檢索出最相關的 Top-12 段落。
BM25:作為一種傳統的基於關鍵字的檢索方法,BM25 擅長捕捉精確的詞彙匹配。在推斷時,查詢也會傳遞給 BM25 搜索(具體使用 Anserini 庫),並收集 Top-12 的 BM25 結果。
Re2G 在此層結合使用了 DPR (一種神經「表示模型」) 和 BM25 (一種詞彙匹配方法)。這兩種方法互補,共同產生一個初步的候選段落池,這兩種方法檢索到的段落隨後會被合併,為後續的重排序階段提供一個更全面且多樣化的候選集。
舉例:
DPR 的檢索結果: DPR 模型會將文檔庫中的所有段落預先編碼成向量,並儲存在一個向量資料庫中,當有一個查詢進來時,DPR 會將這個查詢也編碼成一個向量,然後,它會在向量資料庫中進行「最近鄰搜索」,找出與查詢向量最相似的 K 個段落向量,這些被找出來的 K 個段落,就是 DPR 的「檢索結果」,它們是實際的文本段落。
例如:「尼加拉瀑布位於加拿大和美國的邊界。」BM25 的檢索結果: BM25 演算法會根據查詢中的關鍵字,在文檔庫中計算每個段落與查詢的相關性分數,它會根據這些分數,找出相關性最高的 K 個段落,這些被找出來的 K 個段落,就是 BM25 的「檢索結果」,它們也是實際的文本段落。
例如:「尼加拉瀑布是世界著名的瀑布。」合併指的是將這兩個獨立檢索器(DPR 和 BM25)各自找出來的候選段落列表結合起來,形成一個更大的、包含更多潛在相關段落的集合。
例如:
DPR 可能檢索到段落 A, B, C, D, E。
BM25 可能檢索到段落 C, F, G, H, I。
合併後,初始候選集就可能包含 A, B, C, D, E, F, G, H, I。
重排序層:互動模型的強大能力
重排序層的核心目的是精煉初始檢索結果的排名,並實現來自不同檢索方法結果的合併。
- 模型類型:Re2G 使用基於 Nogueira 和 Cho 序列對分類方法的「互動模型」進行重排序。
機制: 在互動模型中,查詢和段落會作為一個整體輸入到 BERT 變換器中,模型會在兩個序列的所有詞元上共同應用交叉注意力機制,從而捕捉查詢和段落之間更深層次的交互關係。
優勢:透過使用互動模型對來自表示模型的 Top-N 段落進行重排序,Re2G 能夠同時獲得兩種模型類型的優勢:互動模型帶來的更高準確性(因其能進行更細緻的交叉注意力計算),以及表示模型帶來的可擴展性(因其允許高效的初始檢索)。這種設計模式在許多大規模資訊檢索系統中非常有效,平衡了對大型語料庫的快速初始檢索與對較小候選集的精細排名。
初始化與推斷: 重排序器從 NBoost 在 MS MARCO 數據集上訓練的 BERT 模型初始化。在推斷時,從初始檢索層合併後的段落集會傳遞給重排序器進行評分,並選出 Top-5 的段落供生成器使用。
生成層:基於BART的序列生成
生成層負責根據重排序後的段落和查詢生成最終的目標輸出序列。
基礎模型:Re2G 使用基於 BART 的序列到序列生成模型,具體是 $BART_{LARGE}$。BART 結合了雙向編碼器(如 BERT)和自回歸解碼器(如 GPT)的優勢,使其非常適合序列到序列任務,並能有效地整合檢索到的資訊。這種選擇利用了現有的穩健生成模型,並透過外部知識增強了它們的能力。
生成器輸入與輸出:來自重排序器的 Top-5 段落會與原始查詢結合,作為 $BART_{LARGE}$ 的輸入以生成輸出。BART 生成的五個輸出序列隨後會根據重排序器分數的 softmax 進行加權,以產生最終的輸出。這個過程在 RAG 中稱為邊緣化 (marginalization),它確保了檢索到的相關性信息能夠有效指導最終的生成。
四階段訓練方法與線上知識蒸餾
第一階段:DPR 訓練
訓練數據由查詢、正向段落(來自真實標籤的來源資訊)以及「硬負向」段落(從 BM25 檢索但非真實標籤的段落)的三元組組成,這些實例會被批次處理,並且批次中其他實例的正向和硬負向段落會被用作當前實例的「批次負向」,DPR 雙編碼器模型隨後會為每個查詢提供其對正向、硬負向和批次負向段落的概率分佈。此階段的損失函數是正向段落的負對數似然,完成此階段訓練後,語料庫中的所有段落都會使用分層可導航小世界圖 (HNSW) 結合 FAISS 庫進行索引,以便後續高效檢索。
第二階段:生成訓練
此階段的訓練目標是擴展查詢編碼器的訓練,並訓練 BARTLARGE 序列到序列模型以生成最終的目標序列輸出。這個訓練過程與 Lewis 等人描述的 RAG 模型生成訓練方法一致。
第三階段:重排序訓練
重排序器的獨立訓練始於收集訓練集上來自 DPR 和 BM25 的初始檢索結果,這些結果隨後會被合併,並作為重排序器的訓練數據。由於某些數據集可能存在多個正向段落,因此此階段採用的損失函數是這些正向段落負對數似然之和。
第四階段:端到端訓練
端到端訓練帶來了一個特殊挑戰:在 Re2G 中,重排序器的分數而非初始檢索分數用於加權每個序列在生成中的影響。這意味著重排序器可以直接透過目標輸出的真實標籤進行訓練,但查詢編碼器的梯度將為零,因為邊緣化過程不再直接依賴於查詢和段落表示向量的內積。
為了解決這個問題,Re2G 引入了一種新穎的線上知識蒸餾應用。在這種方法中,重排序器作為「教師模型」,為 DPR「學生模型」提供軟標籤。這種知識蒸餾是「線上」發生的,即在重排序器訓練的同時進行,實現了知識從一種架構(互動模型)到另一種架構(表示模型)的轉移。初始檢索(DPR)的損失函數是其在檢索到的段落上給出的概率分佈與重排序器在相同段落上給出的概率分佈之間的 KL 散度。為了平滑這些分佈、防止過度損失並穩定訓練,模型使用了溫度超參數 (T)。這種方法不僅提供了正向和負向實例的信號,還提供了「負向程度」的信號,並且能夠利用更多段落進行訓練(DPR 檢索 12 個段落,而生成只使用 Top-5),從而提供了比二元標籤更豐富的訓練信號。
實驗結果與性能分析
此部分尚未撰寫。
結論
Re2G 在槽填充、問答、事實核查和對話等任務中,無論是檢索還是端到端性能都得到了實質性提升。
本研究的關鍵成果包括:
- 重排序器的有效性。
- 線上知識蒸餾的成功。
- 多源檢索的益處。